3D Object Recognition By Corresponding and Quantizing Neural 3D Scene Representations
Abstract
We propose a system that learns to detect objects and infer their 3D poses in RGB-D images. Many existing systems can identify objects and infer 3D poses, but they heavily rely on human labels and 3D annotations. The challenge here is to achieve this without relying on strong supervision signals. To address this challenge, we propose a model that maps RGB-D images to a set of 3D visual feature maps in a differentiable fully-convolutional manner, supervised by predicting views. The 3D feature maps correspond to a featurization of the 3D world scene depicted in the images. The object 3D feature representations are invariant to camera viewpoint changes or zooms, which means feature matching can identify similar objects under different camera viewpoints. We can compare the 3D feature maps of two objects by searching alignment across scales and 3D rotations, and, as a result of the operation, we can estimate pose and scale changes without the need for 3D pose annotations. We cluster object feature maps into a set of 3D prototypes that represent familiar objects in canonical scales and orientations. We then parse images by inferring the prototype identity and 3D pose for each detected object. We compare our method to numerous baselines that do not learn 3D feature visual representations or do not attempt to correspond features across scenes, and outperform them by a large margin in the tasks of object retrieval and object pose estimation. Thanks to the 3D nature of the object-centric feature maps, the visual similarity cues are invariant to 3D pose changes or small scale changes, which gives our method an advantage over 2D and 1D methods.
Overview of 3DQ-Nets
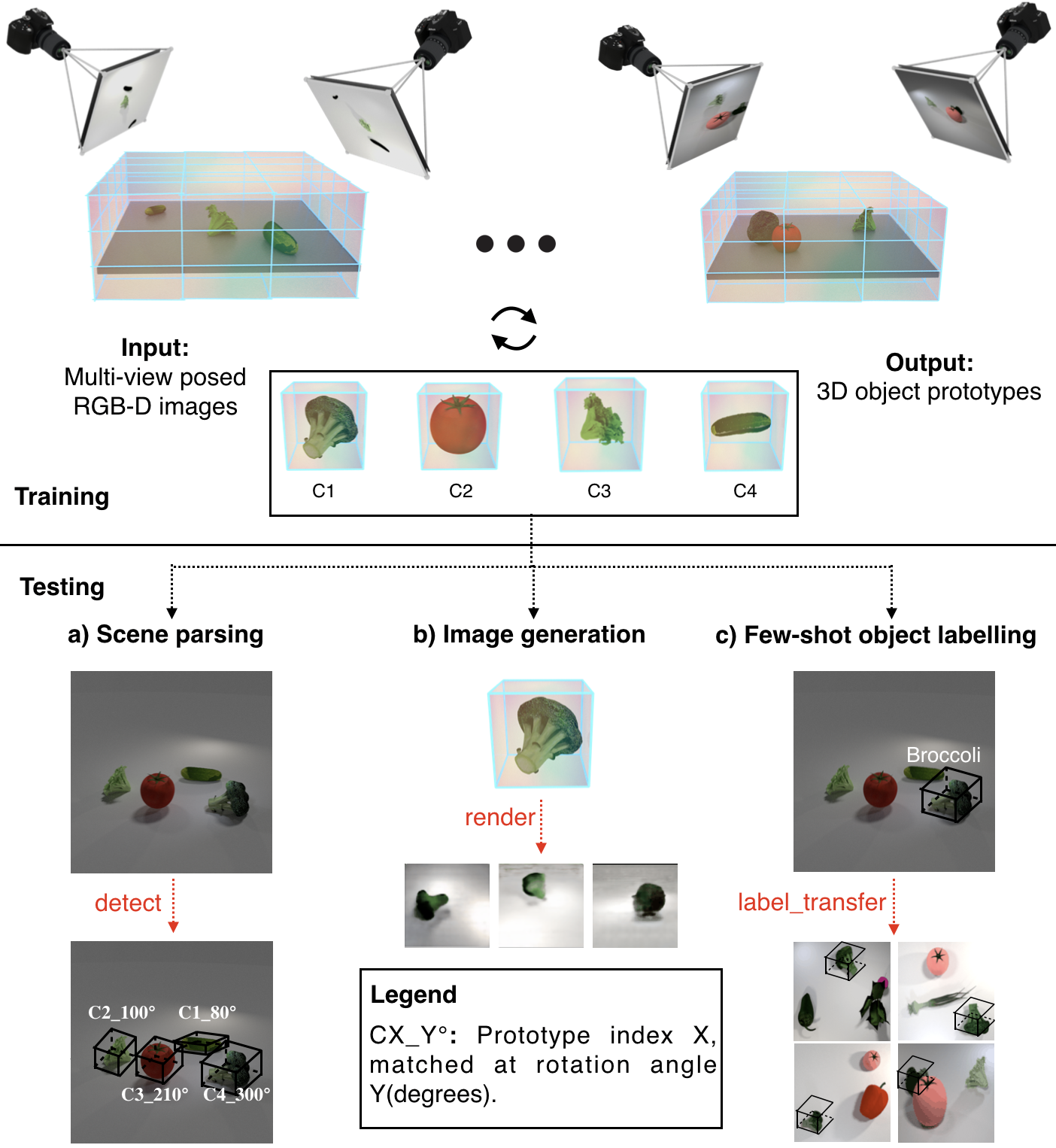
Top: Model overview. Our model takes as input posed RGB-D images of scenes, and outputs 3D prototypes of the objects. Bottom: Evaluation tasks. (a) Scene parsing: Given a new scene, we match each detected object against the prototypes using a rotation-aware check to infer its identity and pose. (b) Image generation: We visualize prototypes with a pre-trained 3D-to-2D image renderer. (c) Few shot object labelling: Assigning a label to a prototype automatically transfers this label to its assigned instances.
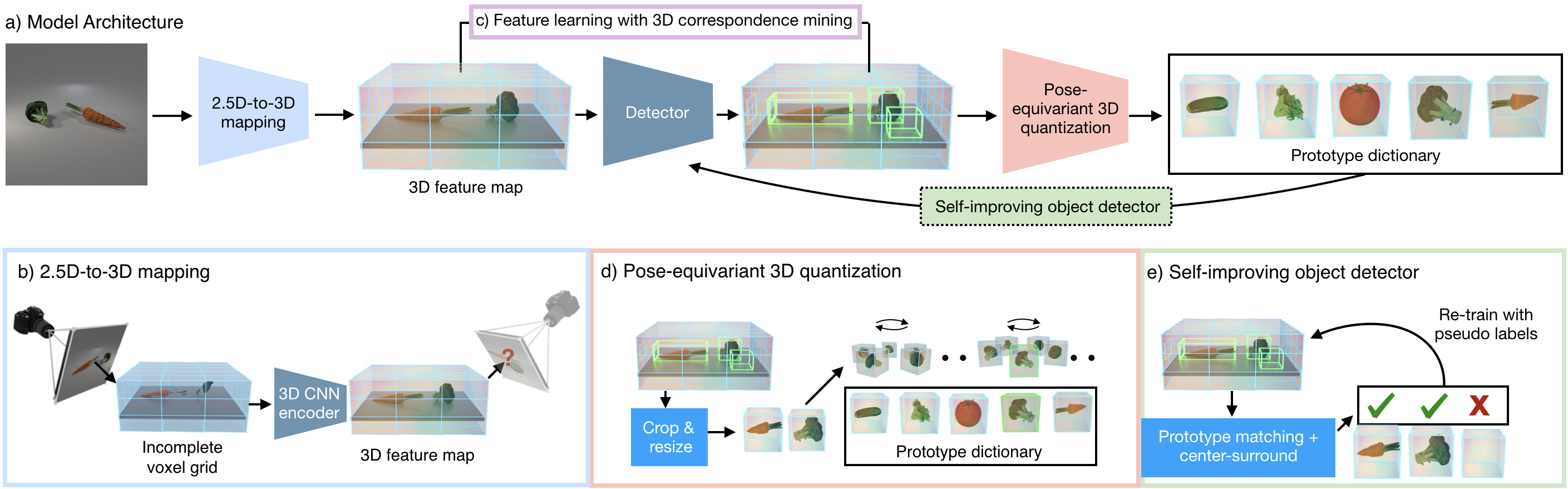
Architecture"Given multi-view posed RGB-D images of scenes as input during training, our model learns to map a single RGB-D image to a completed scene 3D feature map at test time, by training for view prediction (b). The model additionally uses cross-scene and cross-object 3D correspondence mining and metric learning, to make the features more discriminative (c). Finally, using these learned features, our model quantizes object instances into a set of pose-canonical 3D prototypes using rotation-aware matching (d). These learned prototypes help improve our object detector by providing confident positive 3D object box labels (e).
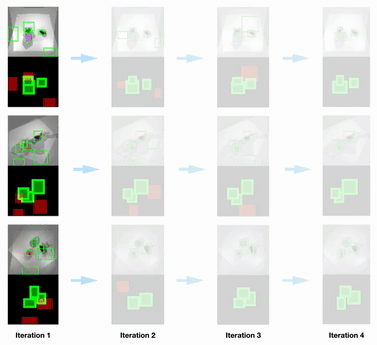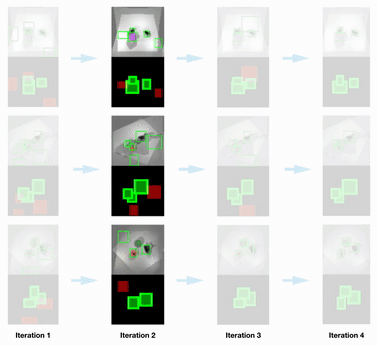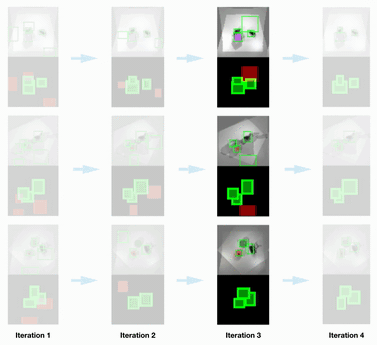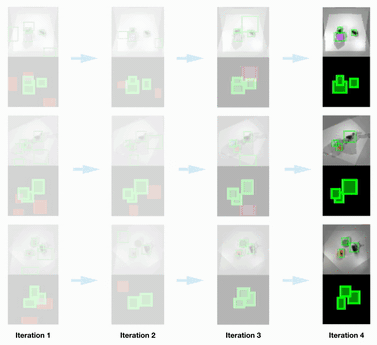
Scene Parsing Results
Citation

3D Object Recognition By Corresponding and Quantizing Neural 3D Scene Representations
Mihir Prabhudesai*, Shamit Lal*, Hsiao-Yu Tung, Adam W Harley, Shubhankar Potdar, Katerina Fragkiadaki arXiv preprint | Code
BibTex
@article{prabhudesai20203d,
title={3D Object Recognition By Corresponding and Quantizing Neural 3D Scene Representations},
author={Prabhudesai, Mihir and Lal, Shamit and Tung, Hsiao-Yu Fish and Harley, Adam W and Potdar, Shubhankar and
Fragkiadaki, Katerina},
journal={arXiv preprint arXiv:2010.16279},
year={2020}
}