Disentangling 3D Prototypical Networks For Few-Shot Concept Learning
Abstract
We present neural architectures that disentangle RGB-D images into objects’ shapes and styles and a map of the background scene, and explore their applications for few-shot 3D object detection and few-shot concept classification. Our networks incorporate architectural biases that reflect the image formation process, 3D geometry of the world scene, and shape-style interplay. They are trained end-to-end self-supervised by predicting views in static scenes, alongside a small number of 3D object boxes. Objects and scenes are represented in terms of 3D feature grids in the bottleneck of the network. We show that the proposed 3D neural representations are compositional: they can generate novel 3D scene feature maps by mixing object shapes and styles, resizing and adding the resulting object 3D feature maps over background scene feature maps. We show that classifiers for object categories, color, materials, and spatial relationships trained over the disentangled 3D feature sub-spaces generalize better with dramatically fewer examples than the current state-of-the-art, and enable a visual question answering system that uses them as its modules to generalize one-shot to novel objects in the scene
Overview of D3DP-Nets
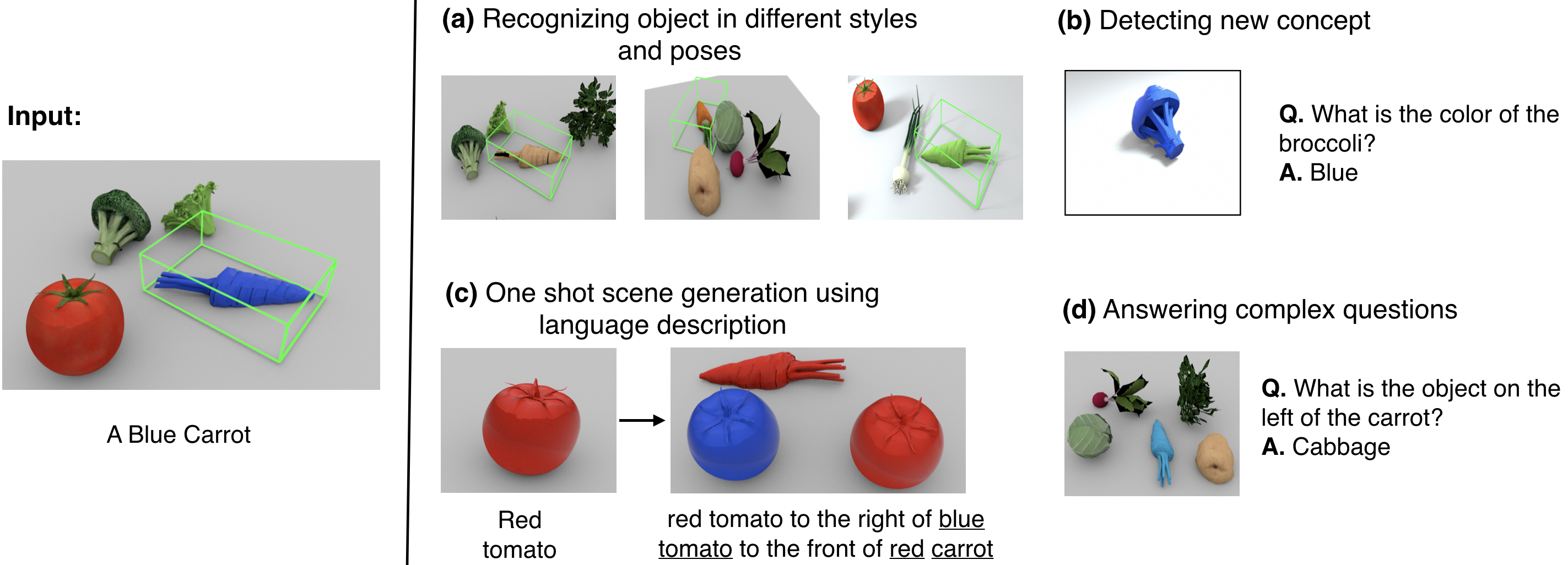
Given a single image-language example regarding new concepts (e.g., blue and carrot), our model can parse the object into its shape and style codes and ground them with Blue and Carrot labels, respectively. On the right, we show tasks the proposed model can achieve using this grounding.(a) It can detect the object under novel style, novel pose, and in novel scene arrangements and viewpoints. (b) It can detect a new concept like blue broccoli. (c) It can imagine scenes with the new concepts. (d) It can answer complex questions about the scene.
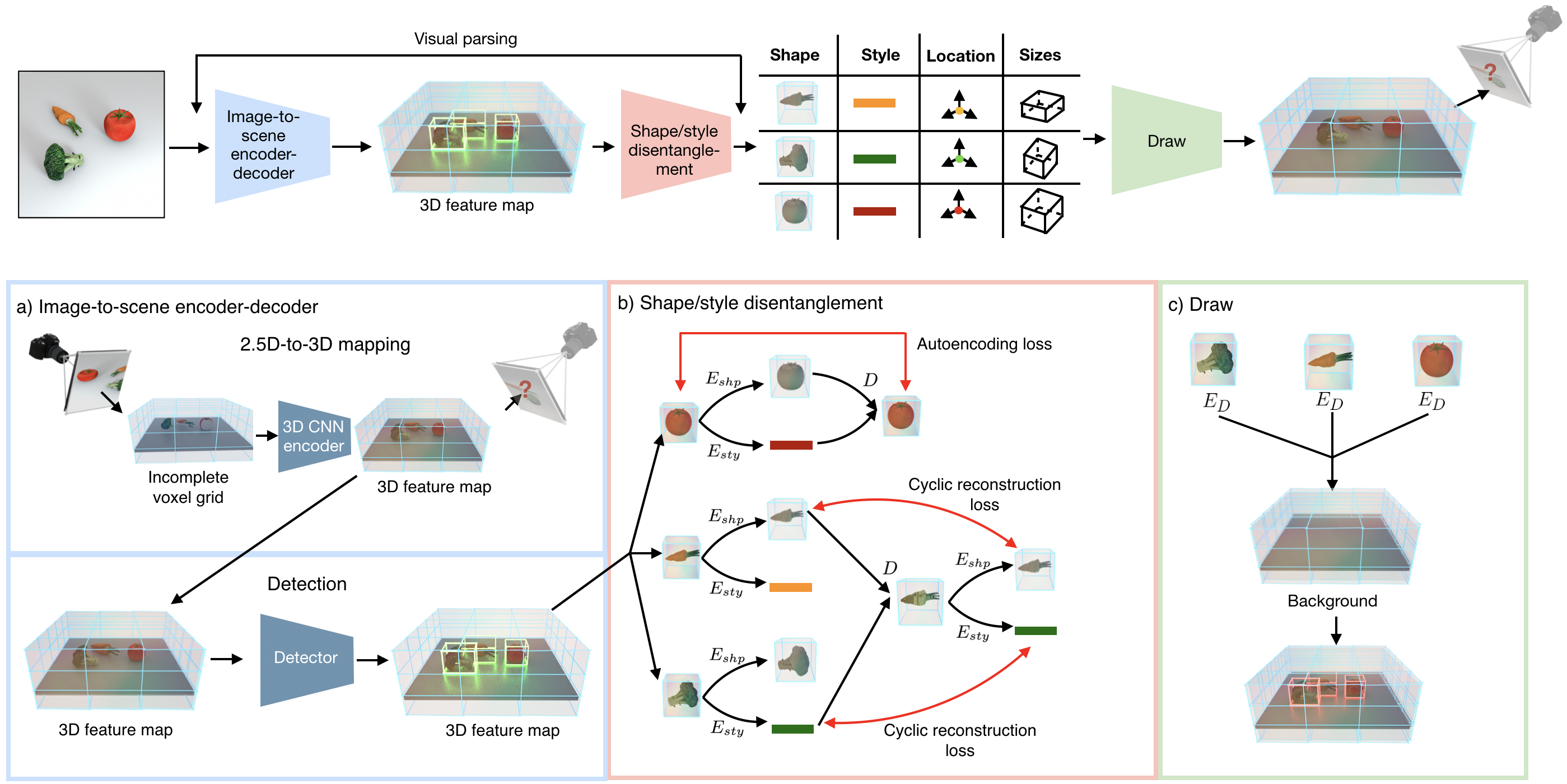
Architecture for disentangling 3D prototypical networks (D3DP-Nets). (a) Given multi-view posed RGB-D images of scenes as input during training, our model learns to map a single RGB-D image to a completed scene 3D feature map at test time, by training for view prediction. From the completed 3D scene feature map, our model learns to detect objects from the scene. (b) In each 3D object box, we apply a shape-style disentanglement autoencoder that disentangles the object-centric feature map to a 3D (feature) shape code and a 1D style code. (c) Our model can compose the disentangled representations to generate a novel scene 3D feature map. We urge the readers to refer the video on the project page for an intuitive understanding of the architecture.
ICLR 2021 video presentation
Citation

Disentangling 3D Prototypical Networks For Few-Shot Concept Learning
Mihir Prabhudesai*, Shamit Lal*, Darshan Patil*, Hsiao-Yu Tung, Adam W Harley, Katerina Fragkiadaki
Arxiv preprint |
Code
BibTex
@article{prabhudesai2020disentangling,
title={Disentangling 3D Prototypical Networks For Few-Shot Concept Learning},
author={Prabhudesai, Mihir and Lal, Shamit and Patil, Darshan and Tung, Hsiao-Yu and Harley, Adam W and Fragkiadaki
, Katerina},
journal={arXiv preprint arXiv:2011.03367},
year={2020}
}
@article{prabhudesai2020disentangling,
title={Disentangling 3D Prototypical Networks For Few-Shot Concept Learning},
author={Prabhudesai, Mihir and Lal, Shamit and Patil, Darshan and Tung, Hsiao-Yu and Harley, Adam W and Fragkiadaki
, Katerina},
journal={arXiv preprint arXiv:2011.03367},
year={2020}
}